AI privacy betekent dat je persoonsgegevens in AI-systemen veilig, rechtmatig en zo beperkt mogelijk verwerkt. In de praktijk komt dat neer op drie dingen: alleen noodzakelijke data gebruiken, privacyrisico’s vooraf beoordelen en passende maatregelen nemen tijdens ontwerp, training en gebruik van het model. Zo voldoe je beter aan de AVG en verklein je de kans op datalekken, ongewenste profilering en modellekken.
- AI privacy gaat verder dan databescherming en kijkt ook naar modelgedrag, inferentie en output.
- De AVG geldt zodra een AI-toepassing persoonsgegevens verwerkt.
- Een DPIA is vaak nodig bij AI met hoog risico, profilering of gevoelige data.
- Dataminimalisatie, toegangsbeheer, logging en outputcontrole zijn vaak de eerste effectieve maatregelen.
- Privacy-preserving AI vraagt om een combinatie van techniek, governance en continue monitoring.
In deze gids leest u wat AI privacy precies is, welke regels gelden, welke risico’s vaak over het hoofd worden gezien en hoe u privacy van AI-systemen praktisch kunt organiseren.
Wat is AI privacy?
AI privacy is het beschermen van persoonsgegevens en andere gevoelige informatie binnen systemen die kunstmatige intelligentie gebruiken. Het gaat niet alleen om de data die u invoert, maar ook om wat een model leert, onthoudt, afleidt en via outputs kan prijsgeven.
Privacy in kunstmatige intelligentie is daarom breder dan traditionele gegevensbescherming. Bij gewone software kijkt u vooral naar opslag, toegang en beveiliging. Bij AI komt daar een extra laag bij: modellen kunnen patronen herkennen, informatie reconstrueren en gevoelige kenmerken afleiden, ook als die niet letterlijk in de invoer staan.
Definitie en scope
AI privacy heeft betrekking op de volledige levenscyclus van een AI-systeem. Denk aan trainingsdata, validatiedata, testomgevingen, prompts, gebruikersinput, modelparameters, logging, API-verkeer en output. In al deze onderdelen kunnen persoonsgegevens voorkomen of opnieuw herleidbaar worden.
Dat zijn niet alleen direct identificeerbare gegevens zoals naam, e-mailadres of klantnummer. Ook locatiegegevens, stemopnames, browsegedrag, medische signalen, apparaatdata en combinaties van schijnbaar onschuldige kenmerken kunnen onder privacy van AI-systemen vallen.
Waarom AI privacy anders is dan gewone privacy
AI-projecten werken vaak met grote hoeveelheden data om voorspellingen of classificaties te verbeteren. Dat botst regelmatig met het AVG-principe van dataminimalisatie. Waar teams geneigd zijn meer data te verzamelen “voor de zekerheid”, vraagt de wet juist om beperking tot wat noodzakelijk is.
Daarnaast ontstaan AI privacy risico’s op plekken waar organisaties niet altijd aan denken. Een model kan trainingsdata memoriseren, via output gevoelige informatie herhalen of op basis van gedrag gevoelige conclusies trekken over gezondheid, inkomen of kwetsbaarheid. Daardoor is privacy-preserving AI niet alleen een juridisch vraagstuk, maar ook een ontwerp- en governancevraagstuk.
AI privacy en AVG: welke regels gelden?
De AVG is het belangrijkste kader voor AI en privacy in Europa. Zodra u persoonsgegevens verwerkt in een AI-toepassing, gelden de bekende privacyregels ook hier. Tegelijk vraagt AVG en AI in de praktijk om extra aandacht, omdat AI-systemen vaak minder transparant zijn en grotere impact kunnen hebben op betrokkenen.
Belangrijke AVG-verplichtingen voor AI-systemen
Voor privacy bij AI zijn deze beginselen extra belangrijk:
- Rechtmatigheid: u moet een geldige grondslag hebben voor de verwerking van persoonsgegevens.
- Doelbinding: data mogen alleen worden gebruikt voor een vooraf bepaald en duidelijk omschreven doel.
- Dataminimalisatie: u gebruikt niet meer persoonsgegevens dan nodig is voor de use case.
- Transparantie: betrokkenen moeten kunnen begrijpen wat het AI-systeem doet en hoe hun gegevens worden gebruikt.
- Juistheid: gegevens moeten correct en actueel zijn, zeker als AI-besluiten daarop steunen.
- Opslagbeperking: persoonsgegevens mogen niet langer worden bewaard dan nodig.
- Integriteit en vertrouwelijkheid: beveiliging, toegangscontrole en logging moeten passend zijn ingericht.
Voor organisaties betekent dit dat AI privacy niet alleen een technisch thema is. U moet keuzes kunnen onderbouwen, documenteren en periodiek opnieuw beoordelen. Dat versterkt ook uw autoriteit en betrouwbaarheid richting klanten, toezichthouders en interne stakeholders.
Wanneer is een DPIA verplicht?
Een DPIA is verplicht wanneer een verwerking waarschijnlijk een hoog risico oplevert voor de rechten en vrijheden van personen. Bij AI is dat vaak het geval, bijvoorbeeld bij grootschalige verwerking, profilering, gevoelige persoonsgegevens, systematische monitoring of geautomatiseerde besluitvorming.
Ook als u innovatieve technologie inzet, meerdere databronnen combineert of werkt met kwetsbare groepen, is een DPIA meestal verstandig. Een goede DPIA helpt om risico’s vroeg zichtbaar te maken en te bepalen welke maatregelen nodig zijn voordat het systeem live gaat.
Wanneer extra alert zijn op een DPIA?
- Bij AI die mensen beoordeelt, rangschikt of profileert
- Bij gebruik van gezondheidsgegevens, biometrie of andere gevoelige data
- Bij grootschalige analyses van klant- of werknemersdata
- Bij koppeling van meerdere datasets
- Bij systemen die aanzienlijke gevolgen hebben voor personen
Geautomatiseerde besluitvorming en profilering
Als een AI-systeem volledig geautomatiseerde besluiten neemt die mensen aanzienlijk raken, gelden extra regels. Denk aan kredietbeoordeling, sollicitatiescreening, verzekeringsacceptatie of frauderisicoscores. In zulke situaties zijn uitleg, menselijke tussenkomst en bezwaarrechten essentieel.
Hier komen privacy, compliance en vertrouwen direct samen. Wie automatische besluitvorming inzet zonder goede waarborgen, loopt niet alleen juridisch risico, maar ook risico op reputatieschade en verlies van klantvertrouwen.
Belangrijkste privacyrisico’s bij AI
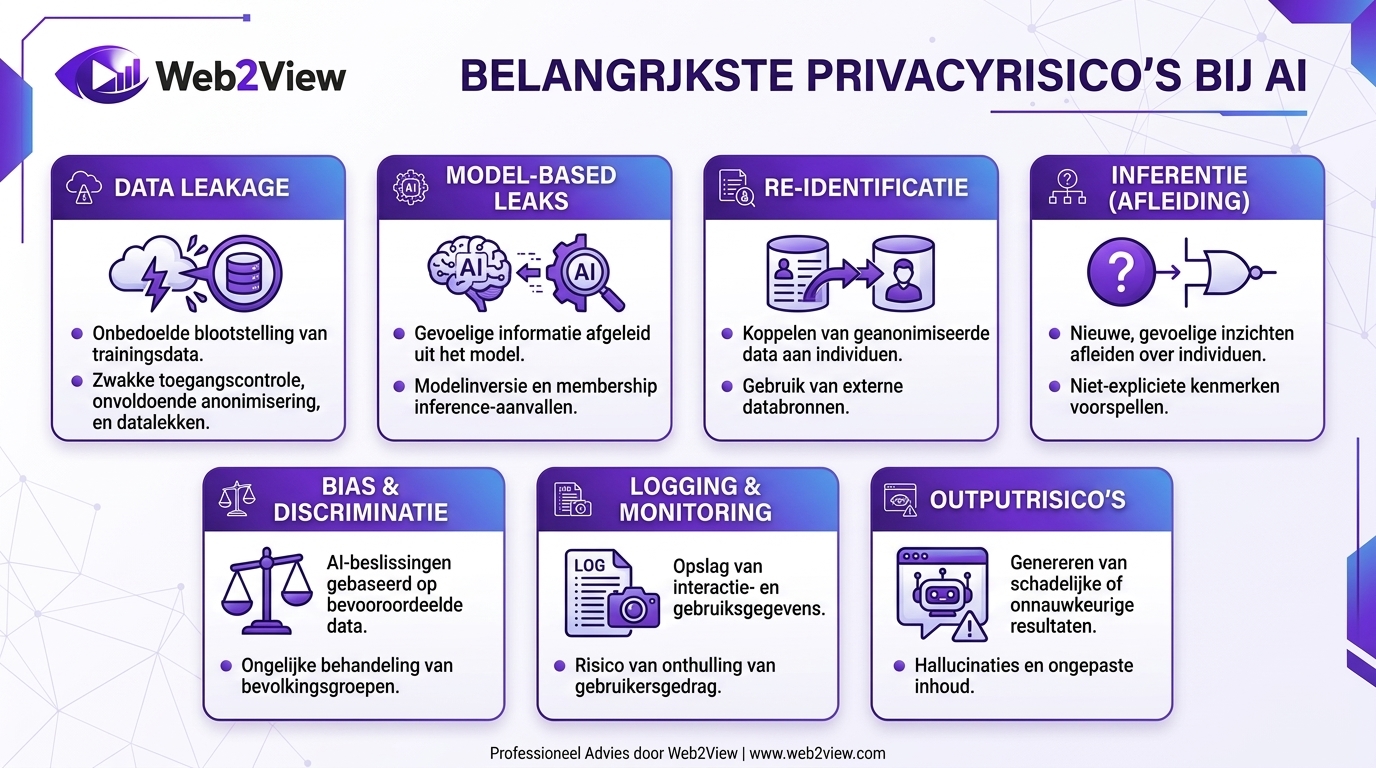
Veel organisaties denken bij AI privacy vooral aan een klassiek datalek. Maar de grootste risico’s zitten vaak in de combinatie van data, modelgedrag en output. Juist daar ontstaan lekken die lastiger te herkennen zijn dan een traditionele beveiligingsfout.
Data leakage en model-based leaks
Data leakage betekent dat gevoelige informatie onbedoeld uitlekt via datasets, prompts, logs, testomgevingen of modeloutput. Dat kan gebeuren als trainingsdata slecht zijn opgeschoond, toegangsrechten te ruim staan of gebruikers met slimme queries meer informatie terugkrijgen dan bedoeld.
Bij membership inference probeert een aanvaller te achterhalen of een persoon deel uitmaakte van de trainingsset. Bij model inversion probeert iemand eigenschappen van de oorspronkelijke data te reconstrueren. Beide risico’s laten zien dat privacy van AI-systemen niet stopt bij encryptie van de brondata.
Re-identificatie en inferentie
Gegevens zijn niet automatisch veilig als u naam en e-mailadres verwijdert. Als datasets worden gecombineerd, kan een persoon alsnog herkenbaar worden. Dat heet re-identificatie. Dit is een belangrijk aandachtspunt bij anonimisering, analytics en AI-training.
Daarnaast kan een model gevoelige informatie afleiden uit indirecte signalen. Bijvoorbeeld dat iemand medische zorg ontvangt, in financiële problemen zit of tot een kwetsbare groep behoort. Zulke inferentie maakt AI en privacy extra complex, omdat de gevoeligheid soms pas ontstaat ná verwerking.
Bias, discriminatie en privacy-overlap
Bias wordt vaak alleen gezien als een fairnessprobleem, maar het raakt ook privacy. Als een model direct of indirect gevoelige kenmerken gebruikt, kunnen mensen worden geprofileerd op basis van etniciteit, religie, gezondheid of sociaal profiel. Dat vergroot niet alleen het risico op discriminatie, maar ook het risico op ongewenste verwerking van bijzondere persoonsgegevens.
Daarom moet privacy in AI altijd samen worden bekeken met datakwaliteit, uitlegbaarheid, governance en modelvalidatie.
Technische maatregelen om AI privacy te beschermen
Er is geen enkele techniek die alle risico’s oplost. Goede AI privacy ontstaat door een combinatie van eenvoudige basismaatregelen en geavanceerdere privacy-preserving technieken. Welke aanpak past, hangt af van de use case, het risiconiveau en de volwassenheid van de organisatie.
Dataminimalisatie en pseudonimisering
De beste eerste stap is meestal ook de eenvoudigste: verwerk alleen de gegevens die echt nodig zijn. Verwijder overbodige velden, beperk bewaartermijnen en gebruik pseudonimisering waar mogelijk. Minder data betekent vaak direct minder risico.
Voor veel organisaties is dit de snelste winst. Het verlaagt de impact van incidenten, maakt compliance eenvoudiger en helpt teams kritischer te kijken naar wat functioneel echt nodig is.
Differential privacy
Differential privacy voegt gecontroleerde ruis toe aan data, statistieken of modeluitvoer. Daardoor wordt het moeilijker om iets over een individueel persoon af te leiden. Deze techniek is vooral bruikbaar bij analyses, rapportages en soms modeltraining.
Het nadeel is dat extra privacy vaak ten koste gaat van nauwkeurigheid. Daarom is differential privacy vooral geschikt wanneer aggregatie belangrijker is dan precisie op individueel niveau.
Federated learning en secure aggregation
Bij federated learning blijven ruwe gegevens lokaal op apparaten of binnen afzonderlijke omgevingen. Alleen modelupdates worden gedeeld. Dat helpt om centrale opslag van persoonsgegevens te verminderen.
Secure aggregation biedt extra bescherming, doordat individuele bijdragen aan modelupdates niet direct zichtbaar zijn. Deze aanpak is relevant in sectoren zoals zorg, financiële dienstverlening en HR, waar privacy van AI-systemen zwaar weegt.
Cryptografische technieken
Secure multi-party computation maakt gezamenlijke berekeningen mogelijk zonder dat partijen hun ruwe data hoeven te delen. Homomorphic encryption maakt het mogelijk om berekeningen uit te voeren op versleutelde gegevens.
Deze technieken bieden sterke bescherming, maar zijn technisch complex en kunnen zwaar zijn qua performance en implementatie. Ze passen daarom vooral bij scenario’s met een hoge vertrouwelijkheidseis.
Anonimisering en synthetische data
Anonimisering probeert persoonsgegevens onomkeerbaar te verwijderen. In theorie valt echt anonieme data buiten de AVG. In de praktijk is dat lastig, omdat herleidbaarheid via koppeling of context vaak toch mogelijk blijft.
Synthetische data kunnen helpen bij testen, ontwikkelen en experimenteren. Toch zijn ze niet automatisch veilig. Als het synthetische patroon te dicht bij echte personen blijft, kan nog steeds privacyrisico ontstaan. Controle en toetsing blijven dus nodig.
Vergelijking van privacy-technieken
| Techniek | Doel | Voordeel | Nadeel | Geschikt voor |
|---|---|---|---|---|
| Dataminimalisatie | Minder persoonsgegevens verwerken | Snel toepasbaar, direct effect | Beperkt soms modelprestatie | Bijna elke AI-use case |
| Pseudonimisering | Directe identificatie beperken | Verlaagt risico in processen | Data blijft vaak persoonsgegevens | Interne analyse en modeltraining |
| Differential privacy | Individuen moeilijk herkenbaar maken | Sterke bescherming tegen afleiding | Mogelijk verlies aan nauwkeurigheid | Statistiek, analyses, ML-training |
| Federated learning | Data lokaal houden | Minder centrale opslag van data | Complexere architectuur | Zorg, finance, device-netwerken |
| Synthetische data | Gebruik van echte data beperken | Nuttig voor testen en experimenten | Niet automatisch risicovrij | Development en validatie |
Organisatorische en procesmatige maatregelen
Technologie alleen is niet genoeg. Veel privacyproblemen ontstaan door onduidelijke verantwoordelijkheden, gebrekkige controles en haast in projecten. Daarom zijn governance en procesafspraken net zo belangrijk als tooling.
Privacy by design en by default
Privacy by design betekent dat u privacy al meeneemt in de ontwerpfase van een AI-project. U wacht dus niet tot het systeem in productie staat. Privacy by default betekent dat standaardinstellingen zo privacyvriendelijk mogelijk zijn.
Concreet betekent dit bijvoorbeeld: alleen noodzakelijke databronnen gebruiken, gevoelige velden uitsluiten, logging beperken tot wat nodig is, output beschermen en testomgevingen niet vullen met echte persoonsgegevens zonder noodzaak.
Rollen, governance en toegangsbeheer
Elk AI-project moet duidelijk eigenaarschap hebben. Leg vast wie verantwoordelijk is voor data, modelkwaliteit, privacy, security, juridische toetsing en incidentrespons. Zonder heldere rollen blijft privacy van AI-systemen al snel tussen teams hangen.
Toegangsbeheer moet niet alleen gelden voor datasets, maar ook voor prompts, modelartefacten, documentatie, logs en dashboards. Het minste-rechtenprincipe is hier een logische basis.
Logging, monitoring en herbeoordeling
AI-systemen veranderen continu. Modellen worden geüpdatet, databronnen wisselen en gebruikersgedrag verandert. Daarom moet AI privacy ook na livegang actief worden bewaakt. Denk aan monitoring van prompts, output, toegangsverzoeken, exportacties en afwijkend gebruik.
Plan daarnaast periodieke herbeoordelingen. Een maatregel die vandaag voldoende is, kan over zes maanden onvoldoende blijken door nieuwe databronnen, nieuwe functionaliteit of gewijzigde regelgeving.
Stapsgewijze implementatiehandleiding voor privacy bij AI
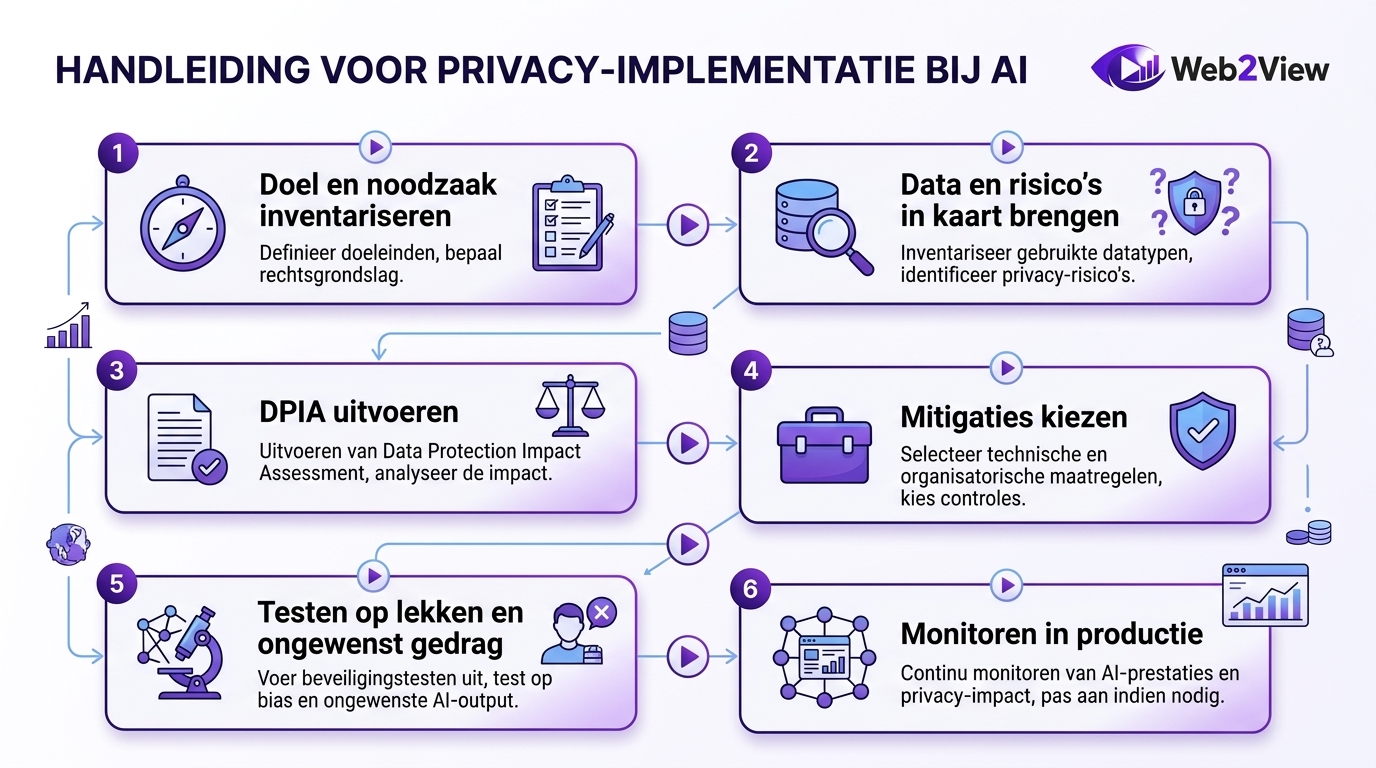
Onderstaand stappenplan helpt organisaties om AI privacy praktisch te organiseren, van eerste idee tot productie.
Stap 1: inventariseer doel, use case en noodzaak
Begin met het doel van het systeem. Welk probleem lost de AI op, en waarom is AI hiervoor nodig? Kijk vervolgens welke persoonsgegevens echt noodzakelijk zijn en welke data u kunt weglaten.
Stap 2: breng data en risico’s in kaart
Maak een overzicht van databronnen, bewaartermijnen, gevoeligheid, leveranciers, doorgiften, toegangsrechten en modelrisico’s. Let daarbij ook op memorisatie, inferentie, re-identificatie en ongewenste output.
Stap 3: voer een DPIA of risicobeoordeling uit
Documenteer de verwerking, beschrijf de risico’s voor betrokkenen en bepaal welke maatregelen nodig zijn. Leg ook vast waarom gekozen maatregelen passend zijn. Herzie dit zodra use case, data of context verandert.
Stap 4: kies passende mitigaties en tools
Kies maatregelen op basis van risico en haalbaarheid. Bij beperkt budget zijn dat vaak eerst dataminimalisatie, pseudonimisering, toegangscontrole, logging en outputbeheer. In zwaardere scenario’s kunt u privacy-preserving machine learning inzetten, zoals differential privacy of federated learning.
Stap 5: test op lekken en ongewenst gedrag
Test modellen niet alleen op performance, maar ook op privacy. Controleer bijvoorbeeld of output gevoelige details prijsgeeft, of prompts data kunnen reconstrueren en of gebruikers meer informatie zien dan nodig is.
Stap 6: monitor continu in productie
Na livegang blijft toezicht nodig. Monitor gebruikspatronen, verdachte queries, wijzigingen in trainingsdata en incidenten. Zo wordt AI privacy een doorlopend beheersproces in plaats van een eenmalige check.
Overzicht: risico, impact en maatregel
| Risico | Impact | Praktische maatregel |
|---|---|---|
| Data leakage | Vertrouwelijke informatie komt naar buiten | Outputfilters, logging, toegangsbeheer, promptbeleid |
| Re-identificatie | Data blijkt alsnog herleidbaar | Dataminimalisatie, toetsing, extra anonimisering |
| Inferentie van gevoelige kenmerken | Privacy-inbreuk zonder directe invoer van gevoelige data | Featurebeperking, modeltesten, DPIA |
| Ongewenste geautomatiseerde besluitvorming | Juridische en reputatieschade | Menselijke controle, transparantie, bezwaarprocedure |
| Te ruime toegang tot modellen of logs | Interne blootstelling van persoonsgegevens | Rolgebaseerde toegang, auditlogs, periodieke review |
Tools, templates en resources
Voor organisaties die privacy-preserving AI willen opzetten, zijn er verschillende bruikbare tools en bronnen beschikbaar. Kies tooling altijd op basis van uw risico’s, architectuur en compliancedoelen.
- TensorFlow Privacy: voor differential privacy in machine learning-workflows
- PySyft: voor privacyvriendelijke en gedistribueerde AI-toepassingen
- DPIA-templates: handig voor standaardisering van privacybeoordelingen
- NIST AI Risk Management Framework: bruikbaar als governancekader
- Richtlijnen van toezichthouders: voor actuele uitleg over AVG, AI en gegevensverwerking
Op de eigen site kunt u hier intern linken naar pagina’s over AVG, informatiebeveiliging, datagovernance, privacy-audits of AI-consultancy. Dat helpt gebruikers sneller verder en versterkt de inhoudelijke samenhang van uw domein.
Praktische checklist voor AI privacy
Gebruik deze checklist als snelle beoordeling voor een nieuw of bestaand AI-project:
- Is het doel van het AI-systeem duidelijk omschreven?
- Is onderbouwd waarom AI nodig is voor deze use case?
- Gebruikt u alleen persoonsgegevens die echt noodzakelijk zijn?
- Is er een geldige AVG-grondslag voor de verwerking?
- Is vastgesteld of een DPIA verplicht of wenselijk is?
- Zijn persoonsgegevens gepseudonimiseerd of waar mogelijk geanonimiseerd?
- Is toegang geregeld op basis van rollen en noodzaak?
- Worden prompts, output en logs gecontroleerd op lekken?
- Zijn bewaartermijnen en verwijderprocessen vastgelegd?
- Zijn betrokkenen goed geïnformeerd over het gebruik van AI?
- Wordt het model periodiek opnieuw beoordeeld op privacyrisico’s?
- Is een incidentproces ingericht voor privacyproblemen in productie?
Praktijkvoorbeelden van AI en privacy
Voorbeeld van een goede aanpak
Een organisatie wil AI inzetten voor interne documentzoeking. Het projectteam begint met een inventarisatie van gevoelige databronnen, toegangsrechten en bewaartermijnen. Alleen goedgekeurde documenten worden opgenomen, gevoelige velden worden gemaskeerd en zoekopdrachten worden gelogd en gecontroleerd.
Hierdoor blijft de meerwaarde van de toepassing hoog, terwijl de privacyrisico’s beheersbaar blijven. Dit is een goed voorbeeld van privacy by design AI in de praktijk.
Voorbeeld van een veelgemaakte fout
Een team test een externe AI-tool met echte klantdata, zonder leveranciersbeoordeling, zonder DPIA en zonder duidelijk promptbeleid. Later blijkt dat vertrouwelijke informatie in een ongeschikte omgeving is ingevoerd en onvoldoende was afgeschermd.
Dit soort incidenten ontstaat meestal niet door onwil, maar door gebrek aan proces, eigenaarschap en duidelijke kaders. Juist daarom zijn governance en interne richtlijnen onmisbaar voor privacy van AI-systemen.
Veelgestelde vragen over AI privacy
AI privacy betekent dat u persoonsgegevens in AI-systemen rechtmatig, veilig en zorgvuldig verwerkt. Het gaat om de data zelf, maar ook om wat een model kan afleiden, onthouden en via outputs kan prijsgeven.
Meestal wanneer het AI-systeem waarschijnlijk een hoog risico vormt voor de rechten en vrijheden van personen, bijvoorbeeld bij profilering, gevoelige data, systematische monitoring of grootschalige verwerking.
Ja, maar alleen als u een geldige grondslag heeft en voldoet aan de AVG. U moet ook kunnen uitleggen waarom deze gegevens nodig zijn en welke maatregelen u neemt om risico’s te beperken.
Niet altijd. In de praktijk blijft re-identificatie soms mogelijk, vooral als datasets worden gecombineerd of het model gevoelige patronen overneemt. Anonimisering moet dus altijd kritisch worden getoetst.
Differential privacy is een techniek die ruis toevoegt om het moeilijker te maken informatie over individuen af te leiden. Het is vooral bruikbaar bij analyses, statistieken en bepaalde machine-learningtoepassingen.
Dat doet u door gericht te testen op ongewenste output, memberships, reconstructie en afwijkende querypatronen. Monitoring van logs, prompts en output is daarbij essentieel.
AI security richt zich op bescherming tegen aanvallen, misbruik en technische kwetsbaarheden. AI privacy richt zich op bescherming van persoonsgegevens, beperking van herleidbaarheid en rechtmatige verwerking.
Nee. De AVG geldt alleen als persoonsgegevens worden verwerkt. Werkt u uitsluitend met echt anonieme data, dan geldt de AVG in principe niet. In de praktijk moet u dat wel goed kunnen aantonen.
Conclusie en next steps
AI privacy betekent dat u persoonsgegevens in AI-systemen zorgvuldig beschermt met juridische, technische en organisatorische maatregelen. Voor organisaties komt dat neer op: alleen noodzakelijke data gebruiken, risico’s vooraf beoordelen, passende waarborgen inbouwen en systemen blijvend monitoren.
Wie AI en privacy serieus aanpakt, voldoet beter aan de AVG, verkleint operationele risico’s en bouwt vertrouwen op bij klanten, medewerkers en partners. Daarmee is AI privacy geen rem op innovatie, maar juist een voorwaarde voor verantwoord en schaalbaar gebruik van AI.