Screaming Frog is een desktoptool waarmee je een website kunt crawlen zoals zoekmachines dat doen. Je gebruikt het om technische SEO-problemen snel te vinden, zoals kapotte links, foutieve redirects, ontbrekende metadata, indexatieproblemen en verkeerde canonicals. Daardoor zie je direct welke technische blokkades organische groei remmen en welke verbeteringen de meeste impact hebben. In deze handleiding leer je stap voor stap hoe je de tool installeert, een eerste crawl uitvoert, rapporten interpreteert en data omzet in concrete acties.
- Je ontdekt in korte tijd technische fouten die indexatie en rankings kunnen beperken.
- Je leert welke rapporten je als eerste moet bekijken en hoe je daarop prioriteert.
- Je ziet wanneer filters, extracties, rendering en integraties echt waarde toevoegen.
- Je begrijpt het verschil tussen de gratis versie en een betaalde licentie.
- Je krijgt een praktische checklist om direct een technische audit uit te voeren.
Wat is Screaming Frog?
Screaming Frog is een website crawler voor technische SEO. De volledige productnaam is SEO Spider. De software bezoekt URL’s op je website, volgt interne links en verzamelt per pagina technische en inhoudelijke signalen. Daardoor krijg je een overzicht van hoe zoekmachines je site waarschijnlijk ervaren.
De tool wordt veel gebruikt voor technische audits, migratiechecks, contentanalyses en kwaliteitscontroles van grote websites. Je kunt er onder meer response codes, redirects, paginatitels, meta descriptions, headings, canonicals, hreflang, afbeeldingen en interne links mee analyseren.
Kernfuncties in één oogopslag
- Crawlen van websites zoals een zoekmachine dat doet
- Opsporen van 3xx-, 4xx- en 5xx-fouten
- Controleren van titels, meta descriptions en headings
- Analyseren van canonical-tags, noindex en hreflang
- Inzicht in interne links, diepte en orphan-achtige signalen
- Exporteren van rapporten naar CSV of Excel
- Koppelen met Search Console, Analytics en prestatiegegevens
- Renderen van JavaScript voor dynamische websites
- Custom extraction via CSS selectors, XPath en regex
Waarom deze tool zo populair is bij technische SEO
De kracht van deze crawler zit in snelheid en diepgang. Binnen enkele minuten kun je honderden of duizenden URL’s analyseren. Dat maakt het makkelijker om patronen te vinden in plaats van losse fouten. Je ziet bijvoorbeeld niet alleen dat één pagina een verkeerde canonical heeft, maar ook of dat probleem op tientallen vergelijkbare pagina’s voorkomt.
Daarnaast is de tool flexibel. Beginners kunnen direct een eenvoudige crawl uitvoeren, terwijl gevorderde gebruikers kunnen werken met segmenten, API-koppelingen, geavanceerde filters en extracties uit de broncode. Daardoor is het zowel een praktische website crawler voor basiscontroles als een sterke technical SEO tool voor diepere analyses.
Installatie en eerste stappen
Systeemvereisten en geheugeninstellingen
De software werkt op Windows, Mac en Linux. Omdat het een desktopprogramma is, gebruik je de rekenkracht en het geheugen van je eigen computer. Voor kleine websites is dat meestal geen probleem. Bij grotere websites kan geheugenbeheer wel belangrijk worden.
Als je veel URL’s wilt crawlen, is het slim om vooraf te controleren of je voldoende RAM beschikbaar hebt. Grote crawls, JavaScript-rendering en meerdere integraties maken een analyse zwaarder. Werk je regelmatig met grote websites, dan loont het om de geheugeninstellingen van de tool aan te passen en onnodige programma’s te sluiten.
Installatie op Windows, Mac en Linux
Download de software via de officiële website en installeer deze lokaal. De installatie is eenvoudig en vergelijkbaar met andere desktopprogramma’s. Na installatie kun je direct een URL invoeren en de eerste crawl starten.
Gebruik je een betaalde licentie, dan kun je die na installatie activeren. Voor een eerste test is de proef- of gratis versie meestal voldoende om de interface te leren kennen en de belangrijkste rapporten te bekijken.
Eerste instellingen voor een zinvolle crawl
Voor een eerste analyse hoef je meestal weinig te wijzigen. Toch is het verstandig om vooraf je doel te bepalen. Wil je een volledige site controleren, alleen een submap analyseren of juist irrelevante URL’s uitsluiten? Hoe scherper je scope, hoe bruikbaarder de uitkomst.
Praktische instellingen om vooraf te overwegen:
- Alleen HTML-pagina’s meenemen of ook afbeeldingen, JavaScript en PDF’s
- Subdomeinen wel of niet crawlen
- Parameters meenemen of uitsluiten
- Robots.txt respecteren of voor analyse tijdelijk negeren
- JavaScript-rendering alleen inschakelen als dat echt nodig is
Je eerste crawl stap voor stap
1. Voer de URL in
Voer het hoofddomein in als je de hele website wilt analyseren. Wil je alleen een specifieke sectie controleren, gebruik dan direct de juiste submap. Dat voorkomt ruis en maakt de uitkomst beter bruikbaar.
2. Start de crawl
Klik op start en laat de crawler de website bezoeken. Tijdens het proces zie je hoeveel URL’s zijn gevonden, welke statuscodes worden teruggegeven en welke bestandstypen worden meegenomen.
3. Bekijk eerst de belangrijkste tabbladen
Open daarna eerst de rapporten die meestal de meeste directe winst opleveren:
- Internal
- Response Codes
- Redirects
- Page Titles
- Meta Descriptions
- H1 en H2
- Images
- Canonicals
4. Filter op fouten en kansen
Gebruik filters om snel de belangrijkste issues zichtbaar te maken. Denk aan 404-fouten, ontbrekende titels, dubbele metadata, niet-indexeerbare URL’s of pagina’s zonder H1.
5. Exporteer alleen de data die je nodig hebt
Exporteer niet automatisch alles. Kies de rapporten die aansluiten op je analysevraag. Zo houd je de dataset overzichtelijk en kun je sneller werken in Excel of Google Sheets.
Belangrijkste rapporten en wat ze betekenen
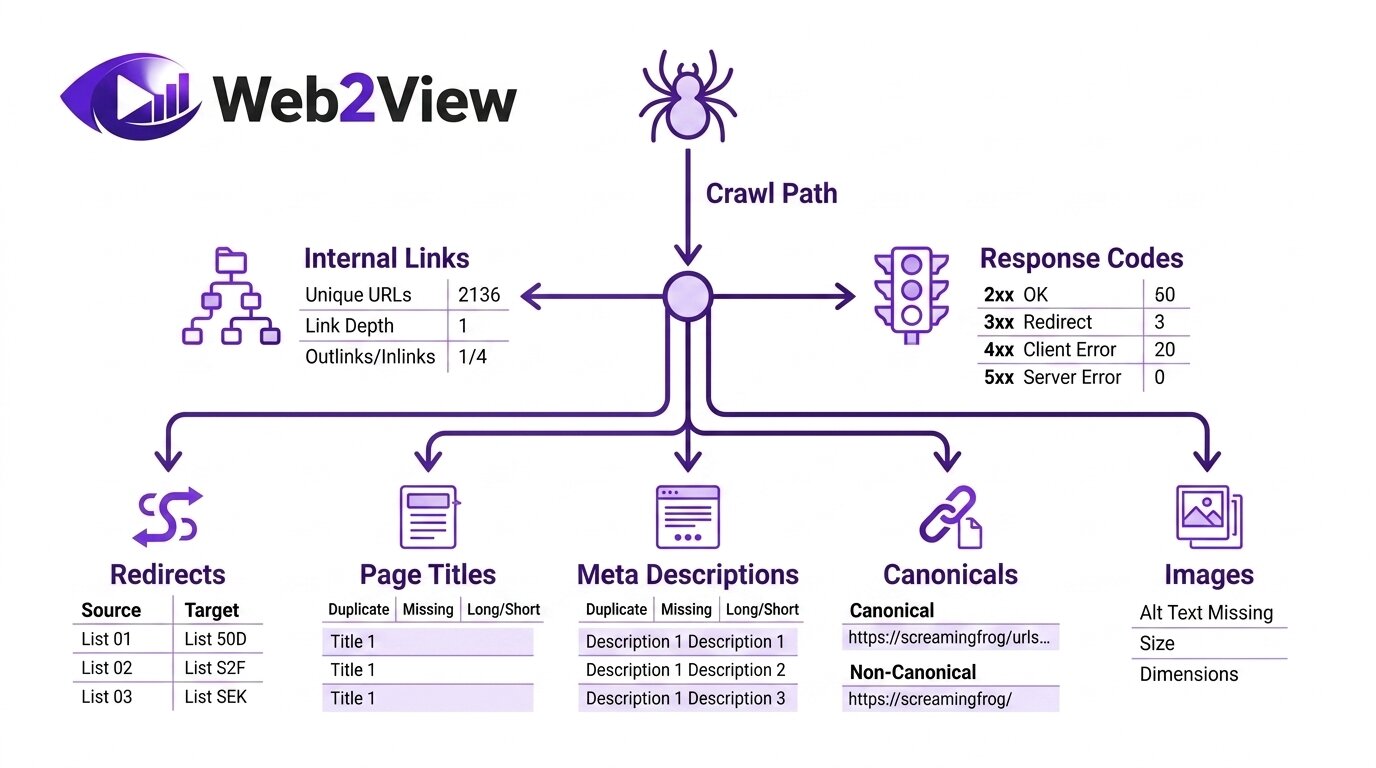
Internal
Hier zie je alle interne URL’s die de crawler heeft gevonden. Dit tabblad is vaak het startpunt van je analyse. Je ziet per pagina onder meer statuscode, contenttype, indexeerbaarheid, canonical-signalen en metadata. Gebruik dit overzicht om snel patronen en opvallende afwijkingen te herkennen.
External
In dit rapport zie je uitgaande externe links. Dat helpt om kapotte externe verwijzingen, oude partnerlinks of onbedoelde verwijzingen naar verkeerde domeinen op te sporen.
Protocol
Dit overzicht laat zien welke URL’s via HTTP of HTTPS worden geladen. Vooral bij migraties en beveiligingscontroles is dit nuttig. Je wilt meestal dat de indexeerbare versie van je website volledig op HTTPS draait.
Response Codes
Dit rapport is essentieel voor technische SEO-audits. Je ziet direct welke URL’s een 200-, 301-, 302-, 404- of 5xx-statuscode teruggeven. Vooral 4xx- en 5xx-fouten verdienen directe aandacht, omdat ze crawlbaarheid en gebruikservaring schaden.
Redirects
Hier controleer je of redirects logisch zijn ingericht. Let op redirect chains, loops en tijdelijke redirects die eigenlijk permanent zouden moeten zijn. Onnodige ketens vertragen crawling en kunnen linkwaarde onnodig verdunnen.
Page titles
In dit rapport vind je ontbrekende, te lange, te korte of dubbele titels. Dit heeft direct invloed op relevantie, indexatie en klikgedrag in de zoekresultaten. Controleer vooral belangrijke landingspagina’s, categoriepagina’s en artikelen met veel zoekverkeer.
Meta descriptions
Meta descriptions zijn geen directe rankingfactor, maar wel belangrijk voor CTR. Gebruik dit tabblad om ontbrekende of dubbele beschrijvingen op te sporen en om pagina’s te vinden waar de snippet waarschijnlijk niet overtuigend genoeg is.
H1 en H2
Deze rapporten helpen bij het controleren van de contentstructuur. Ontbrekende of dubbele headings zijn niet altijd een kritiek probleem, maar geven vaak wel signalen van slordige templates, onduidelijke hiërarchie of gemiste optimalisatiekansen.
Images
Hier zie je afbeeldingen zonder alt-tekst, foutieve image-URL’s en zware bestanden. Dat is relevant voor toegankelijkheid, UX en performance. Grote afbeeldingen kunnen bovendien bijdragen aan tragere laadtijden.
Canonicals
Canonical-tags zijn cruciaal bij duplicate content, filterpagina’s en vergelijkbare URL-varianten. In dit tabblad controleer je of canonical-verwijzingen ontbreken, fout zijn ingesteld of conflicteren met indexatie-instellingen.
Pagination en faceted navigation
Bij webshops en grote contentsites zijn paginering en filterstructuren vaak een bron van SEO-problemen. Controleer of paginapaden logisch zijn opgebouwd, of filterpagina’s ongewenst indexeerbaar zijn en of canonicals hier goed zijn toegepast.
Hreflang
Voor meertalige of internationale websites is dit rapport onmisbaar. Je controleert of taal- en landverwijzingen wederkerig en correct zijn ingesteld. Fouten in hreflang kunnen leiden tot verkeerde landingspagina’s in de zoekresultaten.
Hoe je deze tool gebruikt voor een technische SEO-audit
Een goede audit draait niet om zoveel mogelijk data verzamelen, maar om de juiste problemen vinden en prioriteren. Gebruik de crawler daarom altijd met een duidelijk doel: indexatie verbeteren, crawlbudget efficiënter inzetten, interne links versterken of metadata opschonen.
Welke fouten je snel kunt vinden
- 404-pagina’s en broken links
- Redirect chains en loops
- Ontbrekende of dubbele titels
- Ontbrekende meta descriptions
- Dubbele of ontbrekende H1’s
- Verkeerde canonical-tags
- Noindex-pagina’s die eigenlijk belangrijk zijn
- Afbeeldingen zonder alt-tekst
- Diep gelegen pagina’s met weinig interne links
- Niet-indexeerbare pagina’s die wel verkeer of waarde hebben
Welke tabbladen je als eerste bekijkt
Werk je voor het eerst met de tool, kijk dan eerst naar:
- Internal voor het totaaloverzicht
- Response Codes voor errors en redirects
- Page titles en meta descriptions voor metadata
- Canonicals voor duplicate-contentsignalen
- Images voor zware bestanden en ontbrekende alt-tekst
- H1 voor structuurproblemen
Prioriteren op impact in plaats van op volume
Niet elke fout is even belangrijk. Tien ontbrekende meta descriptions op oude pagina’s zijn meestal minder urgent dan één foutieve canonical op een belangrijke categoriepagina. Prioriteer daarom op drie niveaus:
- Hoog: fouten die indexatie, bereikbaarheid of omzet direct raken
- Middel: problemen die relevantie, CTR of interne structuur verslechteren
- Laag: kleine optimalisaties zonder directe impact
Filters, custom search en slimmer analyseren
Filters maken de tool veel krachtiger. In plaats van alle URL’s tegelijk te bekijken, kun je focussen op één type probleem. Dat versnelt je analyse en maakt de data bruikbaarder.
Praktische filters die vaak direct nuttig zijn
- 4xx-fouten tonen
- Alleen indexeerbare HTML-pagina’s bekijken
- Pagina’s zonder meta description vinden
- Dubbele paginatitels opsporen
- Afbeeldingen met grote bestandsgrootte tonen
- URL’s met parameters isoleren
Include en exclude gebruiken
Met include en exclude-regels stuur je de crawler veel gerichter. Dit is vooral handig bij grote webshops, kennisbanken en meertalige websites. Je kunt bijvoorbeeld alleen een blogmap analyseren of juist zoekresultaten, filterpagina’s en accountomgevingen uitsluiten.
Regex voor patroonherkenning
Regex helpt om URL-structuren en terugkerende patronen te herkennen. Dat is waardevol als je snel specifieke URL-typen wilt isoleren. Denk aan parameterpagina’s, oude jaartallen in slugs of een specifieke sectie van de site.
Praktische voorbeelden:
\?om URL’s met parameters te vinden/blog/om blogartikelen te filteren/20[0-9]{2}/om URL’s met jaartallen te detecteren
Custom extraction en custom search
Een van de krachtigste onderdelen van de software is het kunnen ophalen van specifieke data uit de broncode. Daarmee ga je verder dan standaardrapporten en controleer je precies de elementen die voor jouw website belangrijk zijn.
Wanneer custom extraction handig is
Gebruik deze functie wanneer je wilt controleren of een bepaald element op alle pagina’s aanwezig is. Bijvoorbeeld structured data, auteursinformatie, een prijselement, een reviewscore of een script voor tracking of consent.
Voorbeelden van extracties
- De auteur van blogartikelen uit een specifiek HTML-element halen
- Controleren of productpagina’s een prijsveld tonen
- Testen of een schema-type aanwezig is op belangrijke templates
- Opsporen van een script of tag in de broncode
Voorbeelden met selectors
Voorbeeld met CSS selector:
.author-name
Voorbeeld met XPath:
//script[@type='application/ld+json']
Met custom search kun je daarnaast in de broncode zoeken naar vaste woorden, scripts, codefragmenten of HTML-attributen. Dat is ideaal voor QA, migraties en trackingcontroles.
Data exporteren en verwerken in actiepunten
Een export is alleen waardevol als je de data omzet in beslissingen. Exporteer daarom alleen rapporten die je echt nodig hebt en werk vervolgens met een duidelijke prioritering.
Exporteren naar CSV, Excel of Google Sheets
Vrijwel elk rapport kun je exporteren. Daarna kun je sorteren op statuscodes, metadata, URL-typen of indexeerbaarheid. In Google Sheets of Excel kun je vervolgens kolommen toevoegen voor prioriteit, impact, eigenaar en status.
Een praktische auditworkflow
- Exporteer alleen de belangrijkste fouten per rapport
- Voeg verkeer- of impressiedata toe via andere databronnen
- Label elke issue met impact en moeite
- Groepeer problemen op template of paginatype
- Zet alles om in een actie- en ontwikkelplanning
Prioriteringsmatrix
| Issue | Impact | Moeite | Prioriteit |
|---|---|---|---|
| 404-links op belangrijke pagina’s | Hoog | Laag | Direct oppakken |
| Dubbele titels op categoriepagina’s | Middel | Middel | Korte termijn |
| Ontbrekende alt-teksten op decoratieve afbeeldingen | Laag | Middel | Later optimaliseren |
Integraties en API-koppelingen
Koppelen met Search Console en Analytics
Door crawldata te verrijken met klikken, impressies, CTR en sessies, zie je niet alleen wat technisch fout is, maar ook welke pagina’s zakelijk belangrijk zijn. Dat maakt prioriteren veel slimmer.
Voorbeeld: een foutieve canonical op een pagina zonder verkeer is minder urgent dan hetzelfde probleem op een pagina die veel klikken uit organisch verkeer oplevert.
Prestatiegegevens toevoegen
Via een koppeling met prestatiebronnen kun je snelheidssignalen combineren met technische issues. Zo vind je sneller pagina’s die zowel SEO-problemen als performanceproblemen hebben. Dat is vooral nuttig voor landingspagina’s, productpagina’s en templates met veel verkeer.
Andere toepassingen van API’s
Geavanceerde gebruikers kunnen ook externe databronnen combineren met de crawl. Denk aan backlinkdata, statusinformatie uit andere tools of aanvullende kwaliteitschecks. Zo ontstaat een vollediger auditbeeld dan met alleen crawlerdata.
Log file analysis en combineren met crawl data
Een gewone crawl laat zien hoe jouw website intern is opgebouwd. Logbestanden laten zien hoe zoekmachinebots zich in de praktijk gedragen. Door beide te combineren ontdek je welke URL’s wel of niet worden bezocht en waar crawlbudget verloren gaat.
Waarom log files belangrijk zijn
- Je ziet welke URL’s bots echt bezoeken
- Je ontdekt verspilling van crawlbudget op irrelevante pagina’s
- Je vindt pagina’s die technisch belangrijk zijn maar weinig botactiviteit krijgen
- Je signaleert verschillen tussen theoretische en werkelijke crawlgedrag
Praktische toepassingen
Stel dat filterpagina’s veel botbezoeken krijgen terwijl belangrijke categoriepagina’s weinig aandacht krijgen. Dan heb je een signaal dat je interne links, canonicals of robots-instellingen moet herzien. Juist dit soort analyses maakt log file analysis zo waardevol bij grotere websites.
JavaScript-rendering en dynamische websites
Niet elke website toont content direct in de HTML. Moderne websites laden soms content, links of metadata via JavaScript. In dat geval moet je rendering inschakelen om te zien wat zoekmachines na het uitvoeren van scripts mogelijk waarnemen.
Wanneer rendering nodig is
- Content verschijnt pas na het laden van scripts
- Interne links worden dynamisch toegevoegd
- Metadata wordt client-side ingevuld
- Belangrijke onderdelen ontbreken in de initiële HTML
Beperkingen van rendering
Rendering kost meer tijd en meer geheugen. Grote websites worden daardoor zwaarder om te analyseren. Gebruik deze functie daarom bewust en alleen wanneer de standaardcrawl niet voldoende inzicht geeft.
Voor websites met veel dynamische elementen is dit wel essentieel. Zonder rendering loop je het risico dat je onvolledige data analyseert en belangrijke SEO-signalen mist.
Grote websites crawlen zonder ruis
Ook voor grotere websites is deze software zeer bruikbaar, mits je gestructureerd werkt. Probeer niet alles tegelijk te analyseren. Werk liever per map, template of paginatype.
Praktische aanpak voor grote sites
- Begin met de belangrijkste secties van de site
- Gebruik include- en exclude-regels
- Sluit parameters en irrelevante bestanden uit
- Werk met segmenten zoals categorieën, producten of blogartikelen
- Combineer crawldata met impressies of sessies om impact te bepalen
Zo houd je de analyse overzichtelijk en voorkom je dat je verdrinkt in data zonder duidelijke prioriteiten.
Gratis versie versus betaalde licentie
Veel gebruikers willen weten of de gratis versie voldoende is. Voor kleine websites en eerste analyses is het antwoord meestal ja. Je kunt er de interface mee leren kennen en basale technische controles uitvoeren.
Wanneer gratis voldoende is
- Je een kleine website wilt analyseren
- Je de tool eerst wilt leren kennen
- Je alleen basiscontroles nodig hebt op metadata, links en statuscodes
Wanneer een betaalde licentie logisch is
- Je regelmatig audits uitvoert
- Je grotere websites beheert
- Je integraties, planning en geavanceerde functies nodig hebt
- Je met rendering, custom extraction of diepere exports werkt
Voor SEO-specialisten, bureaus en freelancers verdient een betaalde licentie zich meestal snel terug. Zeker als je vaak technische audits uitvoert of meerdere websites beheert.
Veelgemaakte fouten bij het gebruik van de tool
Zonder doel beginnen
Een crawl zonder duidelijke vraag levert vaak veel data en weinig richting op. Bepaal vooraf wat je wilt onderzoeken: indexatie, metadata, interne links, redirects of rendering.
Te veel URL’s meenemen
Parameters, filters, scripts en irrelevante bestanden kunnen je dataset vervuilen. Gebruik scope, include- en exclude-regels om alleen relevante URL’s te analyseren.
Alleen naar fouten kijken
Niet elke fout is belangrijk. Kijk altijd naar context: welke pagina’s ontvangen verkeer, dragen bij aan omzet of zijn strategisch belangrijk?
Geen opvolging organiseren
Een technische audit zonder actielijst heeft weinig waarde. Zet bevindingen altijd om in concrete tickets, prioriteiten en verantwoordelijkheden.
Verouderde aannames gebruiken
De interface en mogelijkheden van de software veranderen. Controleer daarom altijd of je werkt met actuele instellingen, recente documentatie en de juiste interpretatie van de rapporten.
Praktisch voorbeeld van een analyse
Stel dat je een middelgrote webshop crawlt. In het rapport met response codes zie je tientallen 404-pagina’s. Daarna ontdek je in het interne overzicht dat veel van die URL’s nog intern gelinkt worden. In de metadata-rapporten zie je bovendien dubbele titels op categoriepagina’s, terwijl het canonical-overzicht laat zien dat sommige filterpagina’s naar zichzelf verwijzen terwijl dat niet wenselijk is.
Met één analyse heb je dan direct drie prioriteiten:
- Kapotte interne links herstellen
- Dubbele metadata op categoriepagina’s oplossen
- Canonical-signalen van filterpagina’s corrigeren
Dat laat goed zien waarom deze crawler zo nuttig is: je krijgt snel zicht op patronen die je direct kunt omzetten in verbeteringen.
Stap-voor-stap audit checklist
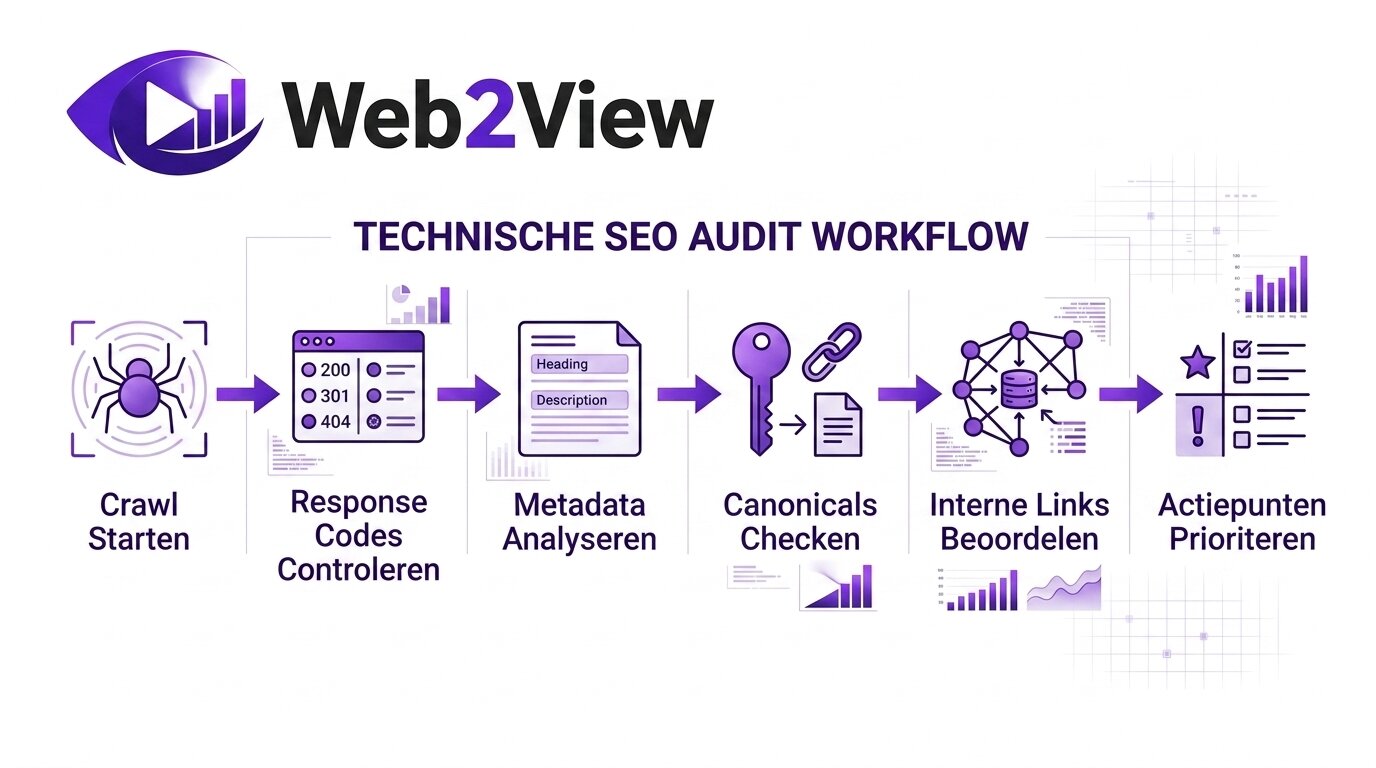
- Crawl de website of een relevante submap
- Controleer response codes op 4xx-, 5xx- en redirectproblemen
- Beoordeel indexeerbaarheid en noindex-instellingen
- Controleer paginatitels en meta descriptions
- Analyseer H1- en H2-structuur
- Controleer canonical-tags en signalen van duplicate content
- Bekijk afbeeldingen op errors, grootte en alt-teksten
- Analyseer interne links en klikdiepte
- Verrijk de crawl met zoek- of verkeersdata
- Maak een actielijst op basis van impact en haalbaarheid
Screaming Frog versus andere tools
| Tool | Sterk in | Minder sterk in | Beste keuze voor |
|---|---|---|---|
| Screaming Frog | Flexibele desktopcrawls, technische diepgang, exports, extracties | Leercurve voor beginners, lokaal afhankelijk van systeemkracht | SEO-specialisten, consultants, bureaus |
| Sitebulb | Visuele rapportages en gebruiksvriendelijkheid | Minder flexibel voor sommige geavanceerde workflows | Gebruikers die meer begeleiding willen in audits |
| Lumar / DeepCrawl | Grootschalige cloudcrawls en enterprise-analyses | Vaak duurder en minder laagdrempelig | Grote organisaties en enterprise-websites |
| SEMrush Site Audit | Gecombineerd platform met meerdere SEO-modules | Minder diepgaand als pure crawler | Marketeers die alles in één omgeving willen |
Wanneer kies je voor deze tool?
Kies hiervoor als je maximale controle wilt over je crawl, snel technische inzichten nodig hebt en flexibel wilt werken met exports, filters, rendering en extracties. Voor veel SEO-professionals is dit nog steeds een van de meest praktische oplossingen voor dagelijkse audits.
Veelgestelde vragen
Het is een desktop crawler die websites scant zoals zoekmachines dat doen. Je gebruikt de tool om technische SEO-problemen, metadatafouten, redirects en interne linkproblemen zichtbaar te maken.
Voor kleine websites en eerste analyses vaak wel. Voor grotere websites, geavanceerde audits en extra functies is een betaalde licentie meestal handiger.
Ja. Het vinden van 404-pagina’s, foutieve interne links en onnodige redirects is juist een van de sterkste toepassingen van de software.
Ja. Als belangrijke content of links pas na scripts verschijnen, kun je rendering inschakelen om een realistischer beeld te krijgen.
Ja. De interface vraagt even gewenning, maar voor basiscontroles is de tool ook voor beginners goed te gebruiken.
Je start een crawl, bekijkt daarna vooral statuscodes, metadata, headings, canonicals, afbeeldingen en interne links, en zet de uitkomsten vervolgens om in een prioriteitenlijst.
Beperk de scope van je crawl, sluit irrelevante URL’s uit, schakel rendering alleen in wanneer nodig en controleer of je systeem voldoende geheugen beschikbaar heeft.
Begin meestal met rapporten voor response codes, redirects, paginatitels, meta descriptions, canonicals en interne links. Daarmee kun je de meeste eerste optimalisaties al prioriteren.
Conclusie
Screaming Frog is een van de meest waardevolle tools voor technische SEO-audits. Je ontdekt snel waar een website fouten bevat, waar crawlbudget verloren gaat en welke verbeteringen de meeste impact hebben. Dat maakt de software geschikt voor zowel beginners als ervaren specialisten.
Wil je sneller technische problemen opsporen, betere prioriteiten stellen en je website structureel verbeteren, dan is deze crawler een logische tool om in je vaste workflow op te nemen. Begin met een gerichte eerste crawl, analyseer de belangrijkste rapporten en vertaal de data altijd naar concrete acties.